Fundamentals of Data Analytics (32130) Week 1
I initially did not take this module, so this week 1 content may be misleading or inaccurate.
Assignment 1: Dream Job (Due 7th March)
Choose 1 Job from the list given, find 2-3 more jobs. Summarize the skills & attributes that are required for the job Based on the skill, judge where you stand and plan on how to narrow that skill gap. Care for word limit (approx 1000 or 2-3 pages 11/12 px Times or Arial)
Visualisation is important for telling a story.
Iris Dataset
most well known dataset in machine learning
150 rows (instance) 50 of each types (setosa, versicolor, virginica) 4 attributes: sepal length, width (cm) and petal length, width (cm)
pretty small sample of data sets, (150 rows, 5 columns) easy to use dataset for classification, clustering, exploratory data analysis (summary stats), correlation
in business analytics flow is CRSIP-DM
Data in daily life
Every digital product you use, you produce personal data which is stored and used by big companies to tailor their services to you.
Data patterns
Bunch of strings and numbers are nothing but just a collection, but the moment you add interpretations on them, they become an information.
Data creation
“If you are not paying for it, you are not the customer; you are the product being sold.”
Data of a single person may not be so valuable, but its a different story when a company collects useful data from a large (millions) number of people.
More and more businesses utilise data to generate more revenue or make their services more profitable.
Big Data’s 5Vs
In early 2000’s big data was defined as data that contains greater variety arriving in increasing volumns and with ever-higher velocity. With the astronomical growth of data and the greater need to value the quality of Data, and consider the reliability - "veracity" of the data. The value of big data increases significantly depending on the insights that can be gained from them.
Volume
data size, scale and amount. Big data volumns can easily reach Petabytes - (1,000,000xGB) even Yottabytes (1,000,000,000x PB) of info
Velocity
speed of data generation.
Variety
complexity of datasets, including both structured and unstructured data in different formats. ex) documents, emails, audio files, images, videos, clickstreams, log files, mobile data, financial transactions. Hundreds, thousands of attributes in multiple dimensions create too many combinations and varieties for traditional database management tools to handle. That’s because there’s no primary key to link these datasets.
Veracity
truthfulness or reliability of the data, which in another word, quality and the data value. Big data must not only be large but also must be reliable in order to achieve value in the analysis of it. external data can vary in quality, affecting accurate analysis.
Value
Worth in information that can be achieved by processing and analysis of large datasets. It also can be measured by an assessment of the other qualities of big data. Value may also represent the profitability of info that is retrieved.
What is Data Analysis
Challenges
Large volumes of high-velocity, complex and variable data that require advanced techniques to enable the capture, storage, distribution, management and the analysis of the information
Opportunities
It can be exploited to enhance business. For example, big data can be used to improve operations, provide better customer service and create personalized marketing campaigns - all of which increase value.
Such challenges & opportunities motivate the industry.
Data Mining
“We are in the info economy, and the way to extract strategic info from those data resources is with Data mining”
Data Analysis
Strategic process where data is examined in order to discover meaningful and valuable patterns, so as to inform conclusions and support decision-making. It operates around inspecting, cleansing, transforming and modelling data.
Supermarket Example
They may use data analytics when deciding which varieties of Coke to order, and in what quantities.
Hypothetical supermarket would collect sales data for each coke variety and perform a simple sum, from that they might think Classic Coke has the most sales, so the supermarket stock more of that. 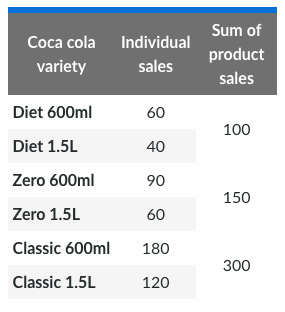
Nappies Example
Walmart analysed its sales data and found beer and diapers are being purchased together on a Friday Night, they theorised that a number of fathers of young children were purchasing those two together on the way home. As a result, Walmart were able to increase sales by placing those two items next to each other in their stores.
Data Finding
Findings from data is called a model
Models help to capture the essense of the discovered knowledge, assist in understanding the problem, and can be used to make future predictions accordingly. It’s useful in downstream fields such as ML which is all about looking through the datasets and trying to build complex model.
Machine Learning
ML algorithm often specifies the way the data is transformed from input-to-output and how the model determines the appropriate mapping (learning) within input-to-output
ML methods is the foundation for most AI solutions
How do machines learn?
Through accumulating & evaluating data. 2 types of ML methods in terms of existing of labels
Supervised Learning
relationship between input and outputs from old data is learnt as example. Can be used to make predictions for new input data.
ex) Decision trees, neural networks, support vector machines, random forest.
Unsupervised Learning
Tries to make sense of the data without labelled responses by representing it in another form. It identifies clusters or groups and frequent patterns in the data.
ex) clustering, association rule mining, neural networks
AI
Broad area that makes machines seem to have human intelligence. AI is a software that solves complex problems.
Nowadays, it’s usage is narrowed to specific usages embedded in everyday life, like face-ID using processing AI, netflix using recommendation engines, google Home using voice recognition tech.
but it is still amazingly powerful.
Modern algorithms are good at digesting gigantic datasets that human could never and they are brilliant is using that data to explain the past and predict the future.
Whether it is prediction, automation, planning, targeting or personalisation, AI is transforming it all.
Common tasks in AI
- reasoning
- knowledge representation
- planning
- learning
- NLP
- perception
- pattern recognition
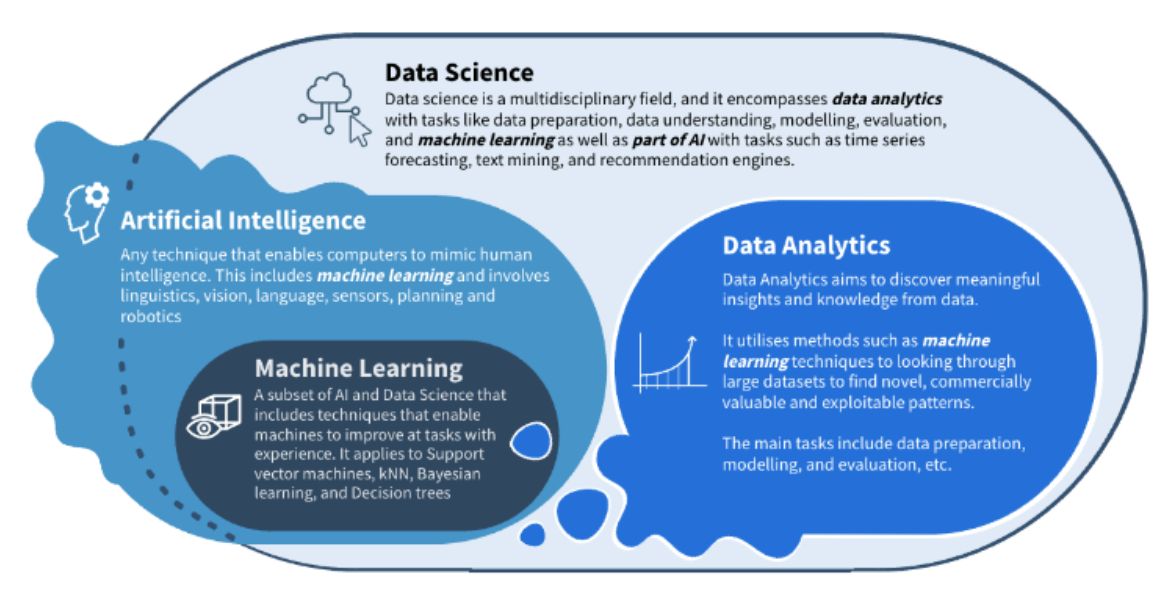
Relationships DA, DS, AI, ML
All of them are related to each other, often used interchangeably and conflated with each other irl. But they are all distinct fields depending on the context
Data science vs Data analytics
difference: scope Data scientist’s role is far broader even though they work on the same data sets So data scientist starts their career as DA.
DS is expected to forecast the future based on past patterns, whike DA extract meaningful insights from various data source.
DS creates questions, DA finds the answers.
Machine Learning vs AI
Machine learning is a subset of AI
Working with Google Colab
remember that computers can’t handle strings, they must be converted to integers
also create hypothesis and test your models and based on the result judge if the performance is good, ready for deployment or need re-evaulation, adjusting for better training.
This is called the iterative procedure for model development and testing before deployment.
KNIME
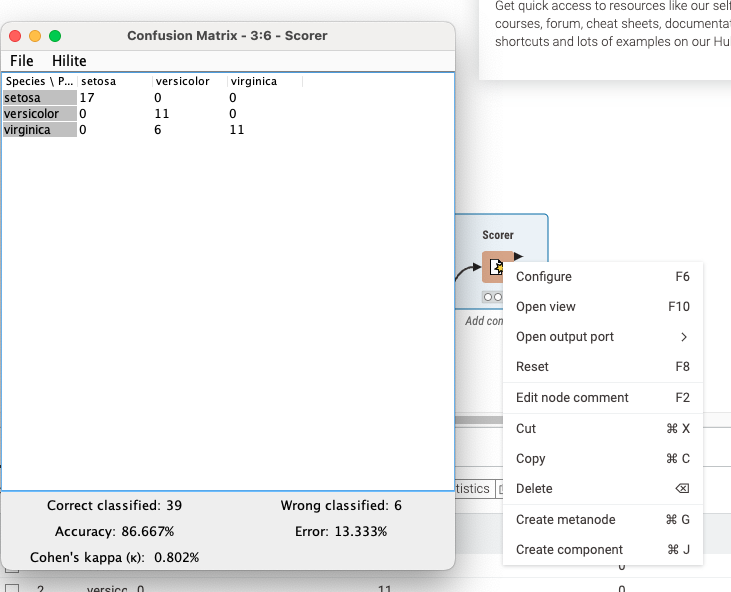
Relative % value of 70 is training and 30 is testing 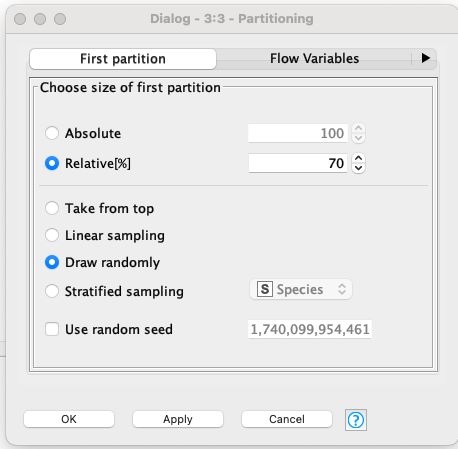
square is model icon
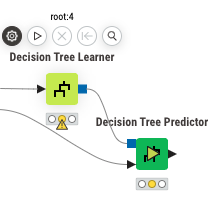
right click scorer to open view to see the performance of the trained model
Workflow pipeline
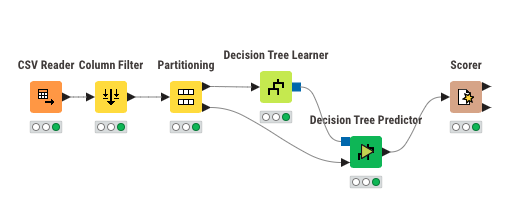
configure and execute.
throughout the module we will learn how to configure each nodes and the techniques will help us manipulate this to create a better work flow.